



У метавсесвіті будуть правила, відмінні від всесвіту, в якому ми живемо. Практично будь-хто зможе створити все, що спадає на думку. У якомусь сенсі правила сильно відрізнятимуться. Але оскільки ми говоримо про новий світ, де компʼютери та люди житимуть і працюватимуть пліч-о-пліч, доцільно знати, як відбуватиметься ця співпраця. Однією з таких спільних робіт є генератор тексту в зображення. Зараз це дуже популярно. Наприклад, OpenAI пропонує свій Craiyon, а Google може похвалитися Imagen. І от компанія Meta, яка є одним з провідних гравців у цій галузі, анонсувала свій власно розроблений механізм генерування зображень за допомогою штучного інтелекту – Make-A-Scene. Як заявили в компанії, новий рушій допоможе людям створювати більш захопливе мистецтво в метавсесвіті.
- Лікарня у метавсесвіті стане реальністю завдяки Thumbay Group: чому це буде корисно?
- Adobe, Epic Games, Meta, Microsoft, NVIDIA, Qualcomm та інші заснували Форум Стандартів Метавсесвіту
- Марк Цукерберг вважає, що метавсесвіт залучить мільярд людей, які витрачатимуть там гроші
- Нейромережа GPT-3 від OpenAI написала про себе статтю для наукового журналу, назвавши себе видатним досягненням науки
- Українець запускає виробництво доступних безпілотників зі штучним інтелектом
В теорії, генератор тексту в зображення є простою річчю. Наприклад, коли ви вимовляєте ключове словосполучення «робот-монстр-ведмідь, що їде на поїзді», механізм спочатку пропускає його через трансформаторну модель, нейронну мережу, а потім «розуміє», що ви сказали, і розвиває контекстне розуміння їхнього звʼязку один з одним. Коли він виконає всі кроки, згадані вище, і зрозуміє, що ви мали на увазі, він створить зображення за допомогою штучного інтелекту, використовуючи набір генеративних змагальних мереж.
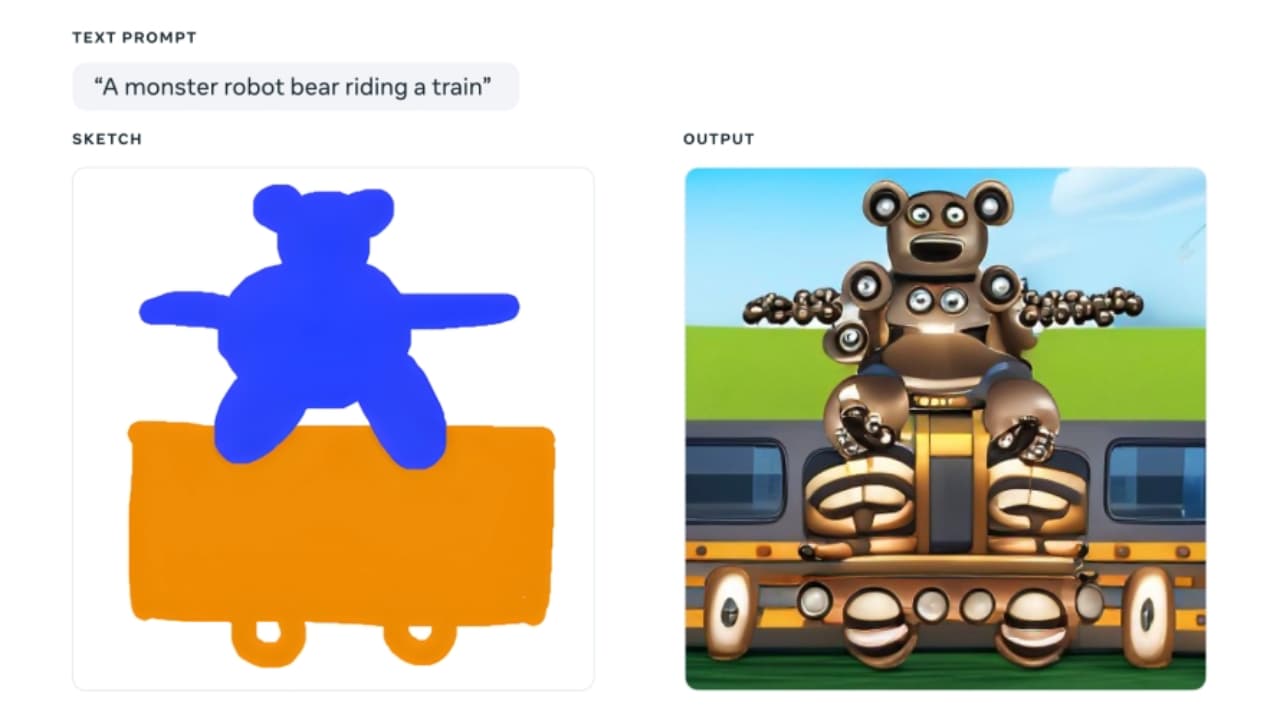
Завдяки розвитку машинного навчання та його здатності до самонавчання, механізми генератора тексту в зображення здатні створювати будь-яку нісенітницю. Можна сказати, що всі рушії працюють за однаковим принципом. Однак, вони відрізняються з огляду обробки штучного інтелекту. Наприклад, Imagen від Google віддає перевагу моделі дифузії, яка вчиться перетворювати шаблон випадкових точок на зображення. Ці зображення спочатку мають низьку роздільну здатність, а потім поступово збільшуються. З іншого боку, Parti від Google спочатку перетворює колекцію зображень на послідовність записів коду, схожу на частини головоломки. Даний текстовий запит потім перекладається на ці записи коду, і створюється нове зображення. Однак, ви повинні знати, що як користувач ви не можете контролювати конкретні аспекти вихідного зображення.
«Щоб реалізувати потенціал штучного інтелекту для просування творчого самовираження люди повинні мати можливість формувати та контролювати контент, який створює система».
Марк Цукерберг, генеральний директор Meta